日記 (2018 年 7 月 7 日)
セグメント木について勉強したのでまとめておきます。
長さ
- 数列のあるインデックスの数を別の数に置き換える
- 数列のある連続した範囲の最小値を求める
普通に数列を配列に保持してこの操作を行おうとすると、 数の置き換えは
以下、 簡単のため
図で表すと以下のような完全二分木になります。 これがセグメント木です。 四角形の左上に書いてある小さい数字は後で説明しますので、 とりあえず無視してください。
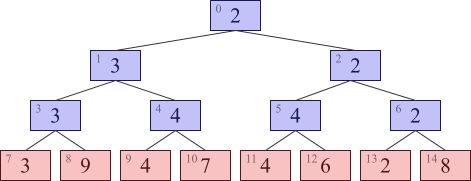
この木の特徴として、 あるノードに書かれている数は、 そこから下向きに枝を辿って到達できる葉ノード (つまり最初に与えられた数列の数が書かれたノード) 全体の最小値になっています。 このことを利用すると、 最初の数列の特定の範囲の最小値を高速に計算できます。
具体例として、 最初に与えられた数列の区間
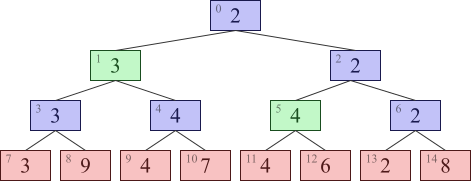
このように、 与えられた区間の最小値は、 セグメント木からうまくノードを見つけてくることで、 そのノードに書かれた数を使って高速に求めることができます。 問題はどのノードの数を使えば良いのかということですが、 これは以下のようにして求められます。
まず、 一番上のノードが使えるか判定します。
一番上のノードには
少し考えると、 この計算が
次に、 最初に与えられた数列のどこかを別の数に書き換えることを考えます。 例えば、 2 番目の数を書き換えたいとします。 すると、 セグメント木の上の方にある数も書き換える必要が生じます。 しかし、 全てを書き換える必要はなく、 今回の場合は下の図の緑のノードを書き換えるだけで十分です。
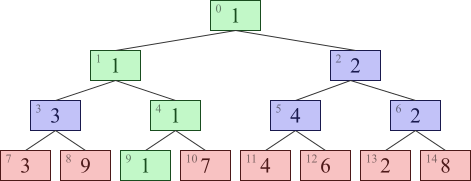
書き換える箇所はセグメント木の高さの分だけなので、 この書き換え処理も
さて、
ところで、 セグメント木は別にある区間の最小値を求めたい場合でなくても使うことができます。 例えば、 ある区間の最大値を求めたい場合でも、 ある区間の総和を求めたい場合でも、 上の説明の 「最小値を求める」 という部分を考えたい操作に置き換えれば実現できます。 しかし、 考える演算が順序に依存する場合、 すなわち左から計算した場合と右から計算した場合で結果が異なり得る場合、 この構造は使えません。 つまり、 考える演算は結合的である必要があります。 また、 最初の数列の長さが 2 の冪でない場合は余った部分を何らかの数で埋める必要がありますが、 この埋める数は演算に影響を与えてはいけません。 言い換えれば、 考えている演算の単位元で埋める必要があります。 以上をまとめると、 結合的かつ単位的な演算が定まってさえいれば良いわけですが、 数学ではそういうものをモノイドと呼びます。 ということで、 セグメント木は、 値の更新とモノイド演算を対数時間で行うことができるデータ構造なわけです。
あとは実装をどうするかですが、 ほとんど上で説明したのをそのままコードに落とし込めば良いだけです。
ただし少し問題になるのが、 木をどう保持するかです。
セグメント木は完全二分木 (全ての葉ノードの深さが同じ) なので、 1 つの配列で保持することができます。
どうするかというと、 木の一番上のノードの値を最初の要素として格納し、 上から 2 番目の段のノードを左から順に続いて格納し、 次は上から 3 番目を、 とすれば良いです。
こうすると、 全体として長さ
なお、 上の図で、 各ノードの左上に小さく書かれていた番号は、 このように木を配列に保持した場合のインデックスを表していたのでした。
ということで、 Java での実装は以下のようになります。
ここでは、 与えられる数列は long で管理することにしました。
コンストラクタの unit には考えているモノイドの単位元を渡し、 operator にはモノイドの演算を渡します。
public static class SegmentTree {
private int size = 1;
private long[] array;
private long unit;
private Operator operator;
public SegmentTree(int n, long unit, Operator operator) {
this.unit = unit;
this.operator = operator;
while (size < n) {
size *= 2;
}
array = new long[2 * size - 1];
Arrays.fill(array, unit);
}
// i 番目の要素を取得する
public long get(int i) {
return array[i + size - 1];
}
// i 番目の要素を data に更新する
public void set(int i, long data) {
i += size - 1;
array[i] = data;
while (i > 0) {
i = (i - 1) / 2;
array[i] = operator.operate(array[i * 2 + 1], array[i * 2 + 2]);
}
}
// 区間 [a, b) に演算を施した結果を取得する
public long find(int a, int b) {
return find(a, b, 0, 0, size);
}
// セグメント木を格納した配列のインデックス i のデータが使えるかを調べる
// インデックス i のノードには区間 [l, r) に演算を施した結果が格納されている
public long find(int a, int b, int i, int l, int r) {
if (a >= r || b <= l) {
// 欲しい区間 [a, b) が調べている区間 [l, r) の完全に外にある場合
// ここの値は使わないので単位元を返しておく
return unit;
} else if (a <= l && b >= r) {
// 欲しい区間 [a, b) が調べている区間 [l, r) の完全に中にある場合
// ここの値は使えるのでそのまま返す
return array[i];
} else {
// 欲しい区間 [a, b) と調べている区間 [l, r) が微妙に重なっている場合
// 1 つ下のノードを見る
int m = (l + r) / 2;
// 子のノードは 2i + 1 と 2i + 2
return operator.operate(find(a, b, i * 2 + 1, l, m), find(a, b, i * 2 + 2, m, r));
}
}
}
@FunctionalInterface
public static interface Operator {
public long operate(long left, long right);
}使うときはこんな感じにします。
int n = 100; // 数列の長さ
SegmentTree tree;
tree = new SegmentTree(n, Long.MAX_VALUE, Math::min); // 範囲内の最小値を取得
tree = new SegmentTree(n, Long.MIN_VALUE, Math::max); // 範囲内の最大値を取得
tree = new SegmentTree(n, 0, (a1, a2) -> a1 + a2); // 範囲内の総和を取得
tree.set(0, 3); // 値のセット
tree.find(1, 7); // 範囲内の演算結果を取得
…さて、 ここまでの話は実は前座で、 本題はここからです。
上のセグメント木では、 範囲の演算結果の取得と 1 点の値の更新が
- 数列のある連続した範囲の数を別の数に置き換える
- 数列のある連続した範囲にモノイド演算を施した結果を求める
上の構造のままでやろうとすると、 更新は範囲の長さ分だけ行う必要があって、 結局最悪で